Using Self-Organizing Maps with SOMbrero to cluster a numeric dataset
07 octobre, 2025
Source:vignettes/c-doc-numericSOM.Rmd
c-doc-numericSOM.RmdBasic package description
SOMbrero implements different variants of the
Self-Organizing Map algorithm (also called Kohonen’s algorithm). To run
the standard version of the algorithm, use the function
trainSOM() on a data frame or matrix with numerical
columns. The standard numeric SOM and its use in SOMbrero
are illustrated below.
This documentation only considers the case of numerical data.
Arguments
The trainSOM function has several arguments, but only
the first one is required. This argument is x.data which is
the dataset used to train the SOM. In this documentation, it is passed
to the function as a matrix or a data frame with numerical variables in
columns and observations of these variables in rows.
The other arguments are the same as the arguments passed to the
initSOM function (they are parameters defining the
algorithm, see help(initSOM) for further details).
Outputs
The trainSOM function returns an object of class
somRes (see help(trainSOM) for further details
on this class).
Graphics
The following table indicates which graphics are available for a numeric SOM.
| What SOM or SC Type |
SOM Energy |
Obs |
Prototypes |
Add |
SuperCluster (no what) |
Obs |
Prototypes |
Add |
|---|---|---|---|---|---|---|---|---|
| (no type) | x | |||||||
| hitmap | x | x | ||||||
| color | x | x | x | x | x | |||
| lines | x | x | x | x | x | x | ||
| meanline | x | x | x | x | ||||
| barplot | x | x | x | x | x | x | ||
| pie | x | x | ||||||
| boxplot | x | x | x | x | ||||
| 3d | x | |||||||
| poly.dist | x | x | ||||||
| umatrix | x | |||||||
| smooth.dist | x | |||||||
| mds | x | x | ||||||
| grid.dist | x | |||||||
| words | x | |||||||
| names | x | x | ||||||
| grid | x | |||||||
| dendrogram | x | |||||||
| dendro3d | x |
First case study: simulated data in
The first case study shows the clustering of points randomly distributed in the square . The data are generated by:
set.seed(4031719)
the.data <- data.frame("x1" = runif(500), "x2" = runif(500))
ggplot(the.data, aes(x = x1, y = x2)) + geom_point() + theme_bw()
Training the SOM
The numeric SOM algorithm is used to cluster the data:
set.seed(1105)
# run the SOM algorithm with 10 intermediate backups and 2000 iterations
my.som <- trainSOM(x.data=the.data, dimension=c(5,5), nb.save=10, maxit=2000,
scaling="none", radius.type="letremy", topo="square",
dist.type = "letremy")The energy evolves as described in the following graphic:
plot(my.som, what="energy")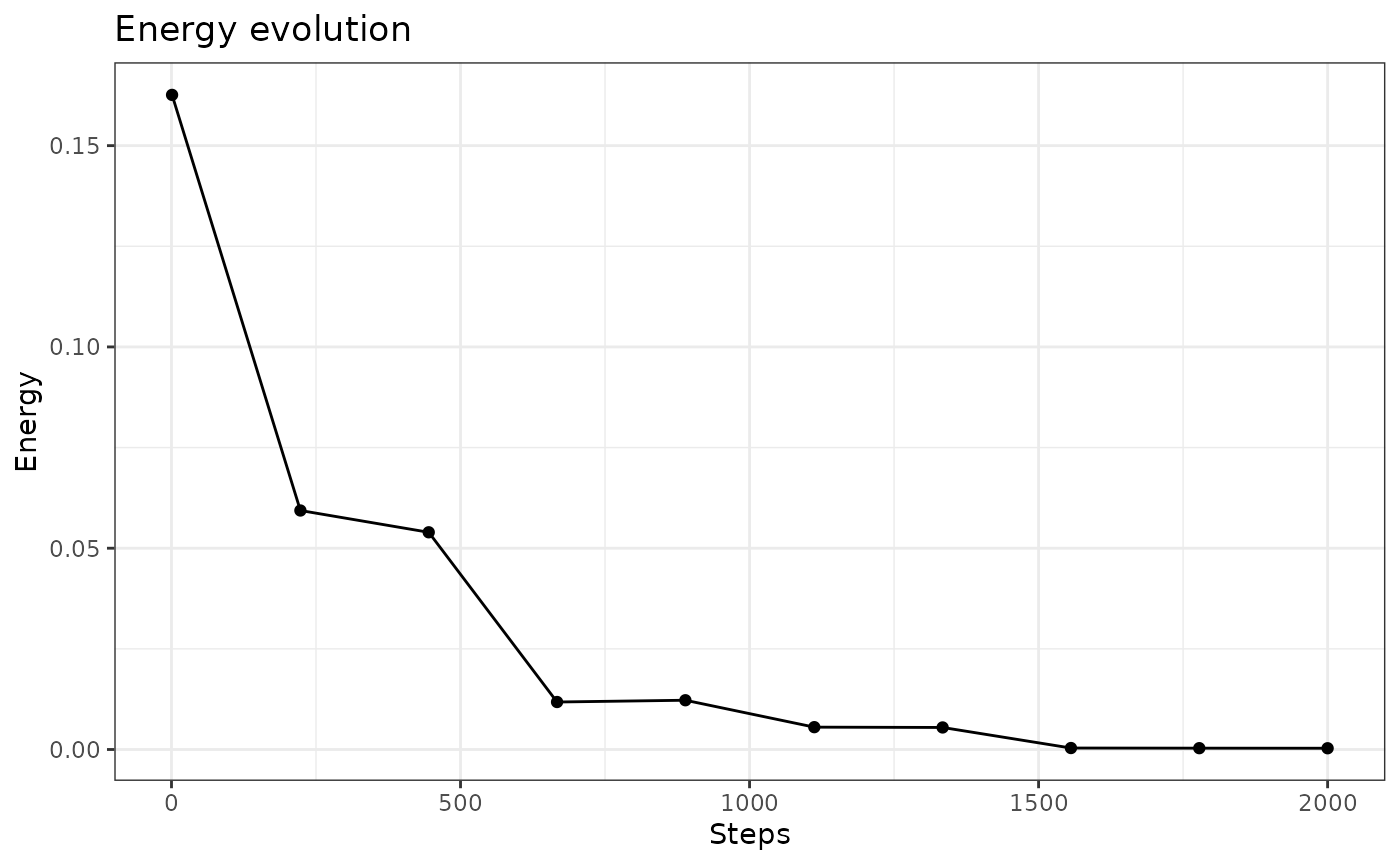
Clustering
The resulting clustering distribution can be visualized by the hitmap:
plot(my.som, what = "obs", type = "hitmap")
The observations are almost uniformly distributed on the map.
The clustering component allows us to plot the initial data according to the final clustering.
# prepare a vector of colors
my.colors <- rainbow(prod(my.som$parameters$the.grid$dim))[my.som$clustering]
# points depicted with the same color are in the same final cluster
plot(my.som$data[,1], my.som$data[,2], col=my.colors, pch=19, xlab="x1",
ylab="x2", main="Data according to final clustering")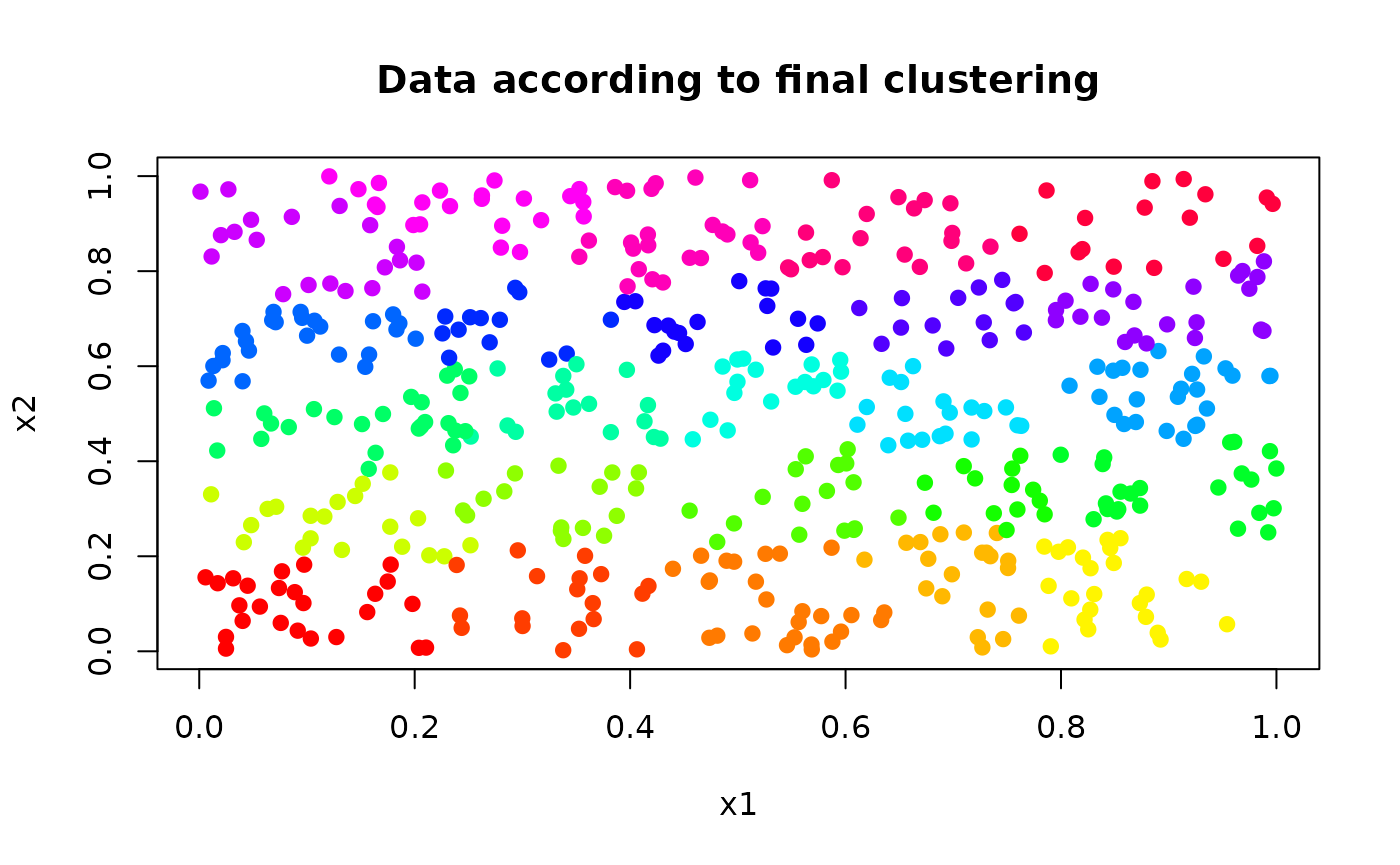
Clustering interpretation
The values of the prototypes can be represented with the plot function and help interpret the clusters:

plot(my.som, what="prototypes", type="color", var=2)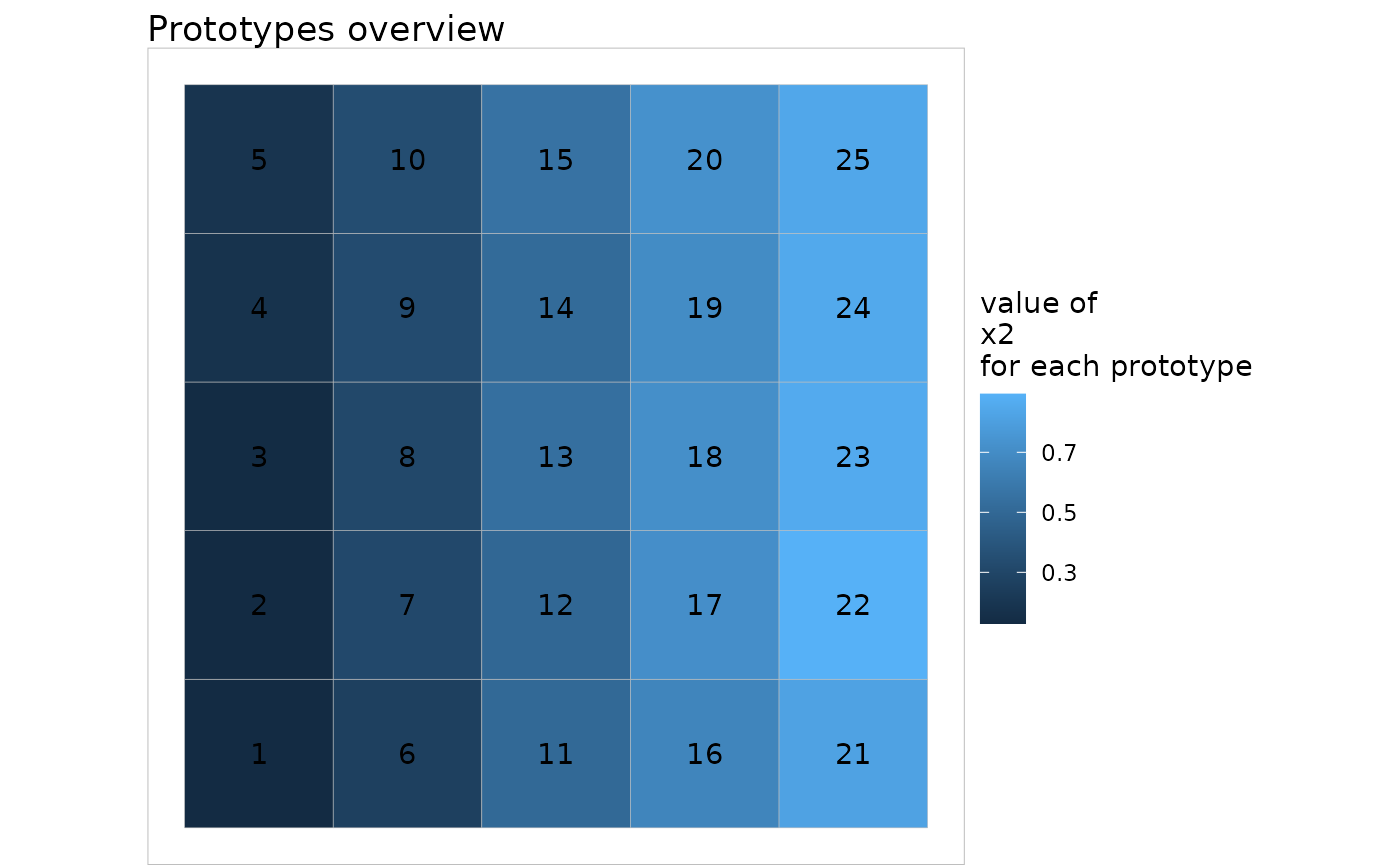
Here, the interpretation is simple enough: high values of the first variables x1 are located at the top of the map and small values at the bottom of the map. Large values of x2 are located at the right hand side of the map, whereas, small values are located at the left hand side.
We obtain the same results with a similar plot on the observation mean values:

plot(my.som, what="obs", type="color", var=2)
The prototypes coordinates are also registered for each intermediate
backup so they can be displayed on different graphics to see the
evolution in the prototype organization.

At the beginning of the algorithm, the prototypes are randomly distributed in [0,1]^2 and then, they organize as a regular rectangular grid in .
Second case study: the iris dataset
This second case study is performed on the famous (Fisher’s or Anderson’s) iris data set that gives the measurements in centimeters of the variables sepal length and width and petal length and width, respectively, for 50 flowers from each of 3 species of iris (setosa, versicolor, and virginica).
Training the SOM
NB: In the following analysis, variables are centered and scaled to unit variance, which is the default behavior of the algorithm.
The first four variables of the data set (that are the numeric variables) are used to map each flower on the SOM grid.
set.seed(255)
# run the SOM algorithm with verbose set to TRUE
iris.som <- trainSOM(x.data = iris[,1:4], dimension = c(5,5), verbose = TRUE,
nb.save = 5, topo = "hexagonal")## Self-Organizing Map algorithm...
##
## Parameters of the SOM
##
## SOM mode : online
## SOM type : numeric
## Affectation type : standard
## Grid :
## Self-Organizing Map structure
##
## Features :
## topology : hexagonal
## x dimension : 5
## y dimension : 5
## distance type: euclidean
##
## Number of iterations : 750
## Number of intermediate backups : 5
## Initializing prototypes method : random
## Data pre-processing type : unitvar
## Neighbourhood type : gaussian
##
## 0 % done
## 10 % done
## 20 % done
## 30 % done
## 40 % done
## 50 % done
## 60 % done
## 70 % done
## 80 % done
## 90 % done
## 100 % done
iris.som## Self-Organizing Map object...
## online learning, type: numeric
## 5 x 5 grid with hexagonal topology
## neighbourhood type: gaussian
## distance type: euclideanAs the energy is registered during the intermediate backups, we can have a look at its evolution.
plot(iris.som, what="energy")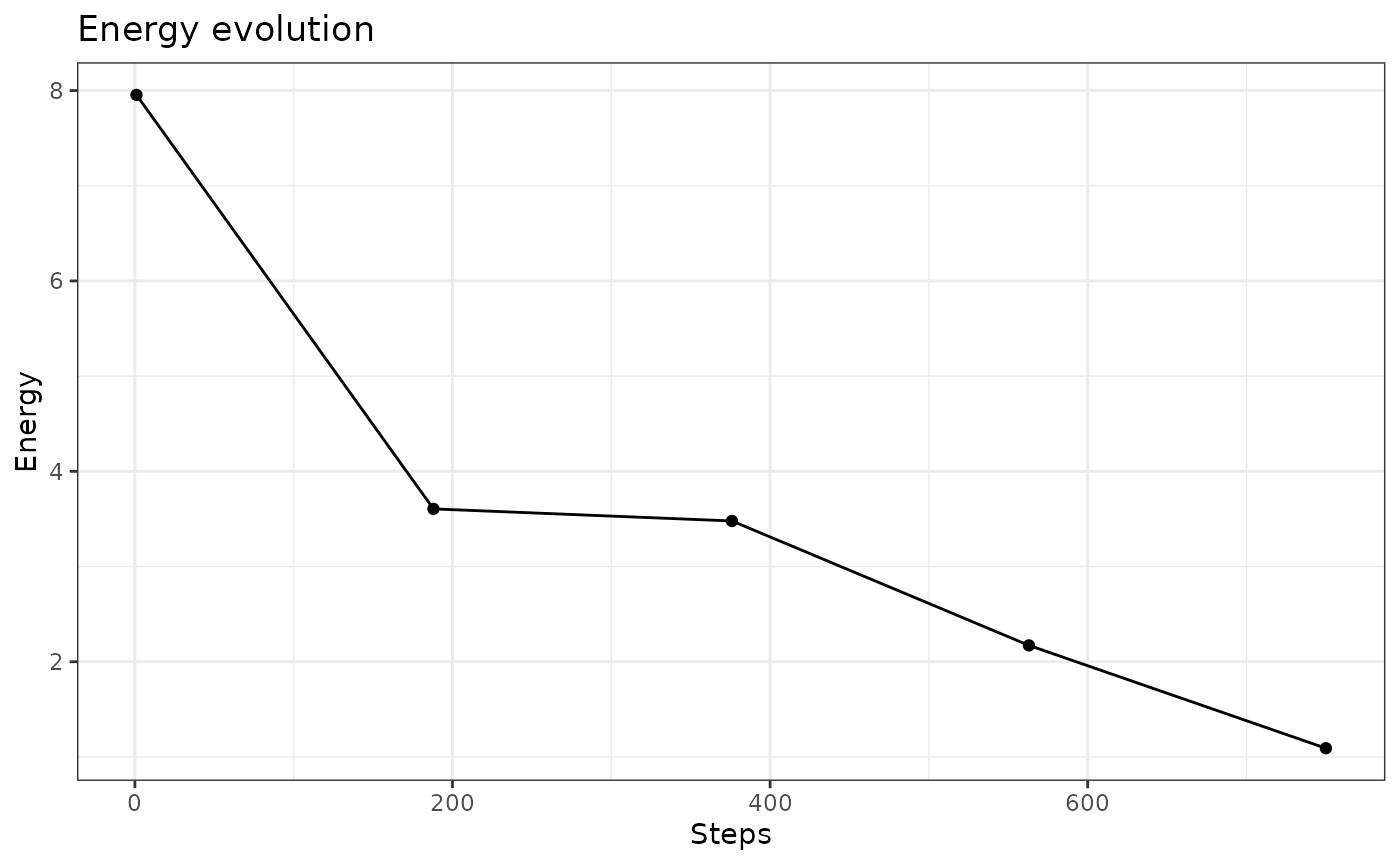
Here the energy does not stabilize as in the case of
dist.type="letremy" because the Gaussian annealing of the
neighborhood is continuous and not stepwise.
Resulting clustering
The clustering component contains the final classification of the dataset. It is a vector with length equal to the number of rows of the input dataset.
iris.som$clustering## 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
## 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5 5
## 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40
## 5 5 5 5 5 4 5 5 5 5 5 5 5 5 5 5 5 5 5 5
## 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60
## 5 2 5 5 5 5 5 5 5 5 23 23 21 6 16 6 23 1 23 1
## 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80
## 1 18 6 17 1 23 17 1 11 1 23 11 16 11 17 23 21 21 17 1
## 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100
## 1 1 6 16 12 25 23 11 12 6 6 18 6 1 6 12 6 17 1 6
## 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120
## 21 16 21 21 21 21 6 21 21 21 21 21 21 16 21 21 21 21 21 11
## 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140
## 21 16 21 21 21 21 16 22 21 21 21 21 21 16 16 21 21 21 22 21
## 141 142 143 144 145 146 147 148 149 150
## 21 21 16 21 21 21 21 21 21 22
table(iris.som$clustering)##
## 1 2 4 5 6 11 12 16 17 18 21 22 23 25
## 11 1 1 48 11 5 3 10 5 2 41 3 8 1which can also be visualized by a hitmap plot:
plot(iris.som, what="obs", type="hitmap")
To assess the relevance of each explanatory variable in the
definition of the clusters, the function summary includes
an ANOVA with the predictor being the clustering, for each (numeric)
input variable.
summary(iris.som)##
## Summary
##
## Class : somRes
##
## Self-Organizing Map object...
## online learning, type: numeric
## 5 x 5 grid with hexagonal topology
## neighbourhood type: gaussian
## distance type: euclidean
##
## Final energy : 1.091265
## Topographic error: 0.1466667
##
## ANOVA :
##
## Degrees of freedom : 13
##
## F pvalue significativity
## Sepal.Length 43.463 0 ***
## Sepal.Width 17.240 0 ***
## Petal.Length 298.228 0 ***
## Petal.Width 173.062 0 ***Here, all variables have significantly different means among the different clusters and can thus be considered to be relevant for the clustering definition.
Another useful function is predict.somRes. This function
predicts the neuron to which a new observation would be assigned. The
first argument must be a somRes object and the second one
the new observation. Let us have a try on the first observation of the
iris data set:
# call predict.somRes
predict(iris.som, iris[1,1:4])## 5
## 5
# check the result of the final clustering with the SOM algorithm
iris.som$clustering[1]## 1
## 5Clustering interpretation
Graphics common to observations and prototypes
Some graphics are shared between observations and prototypes and can be used to display the prototypes’ or the observations’ values for the different variables in the neurons of the map. For observations, the mean values are sometimes displayed instead of the individual values.

plot(iris.som, what = "obs", type = "color", variable = 2)
plot(iris.som, what = "obs", type = "color", variable = 3)
plot(iris.som, what = "obs", type = "color", variable = 4)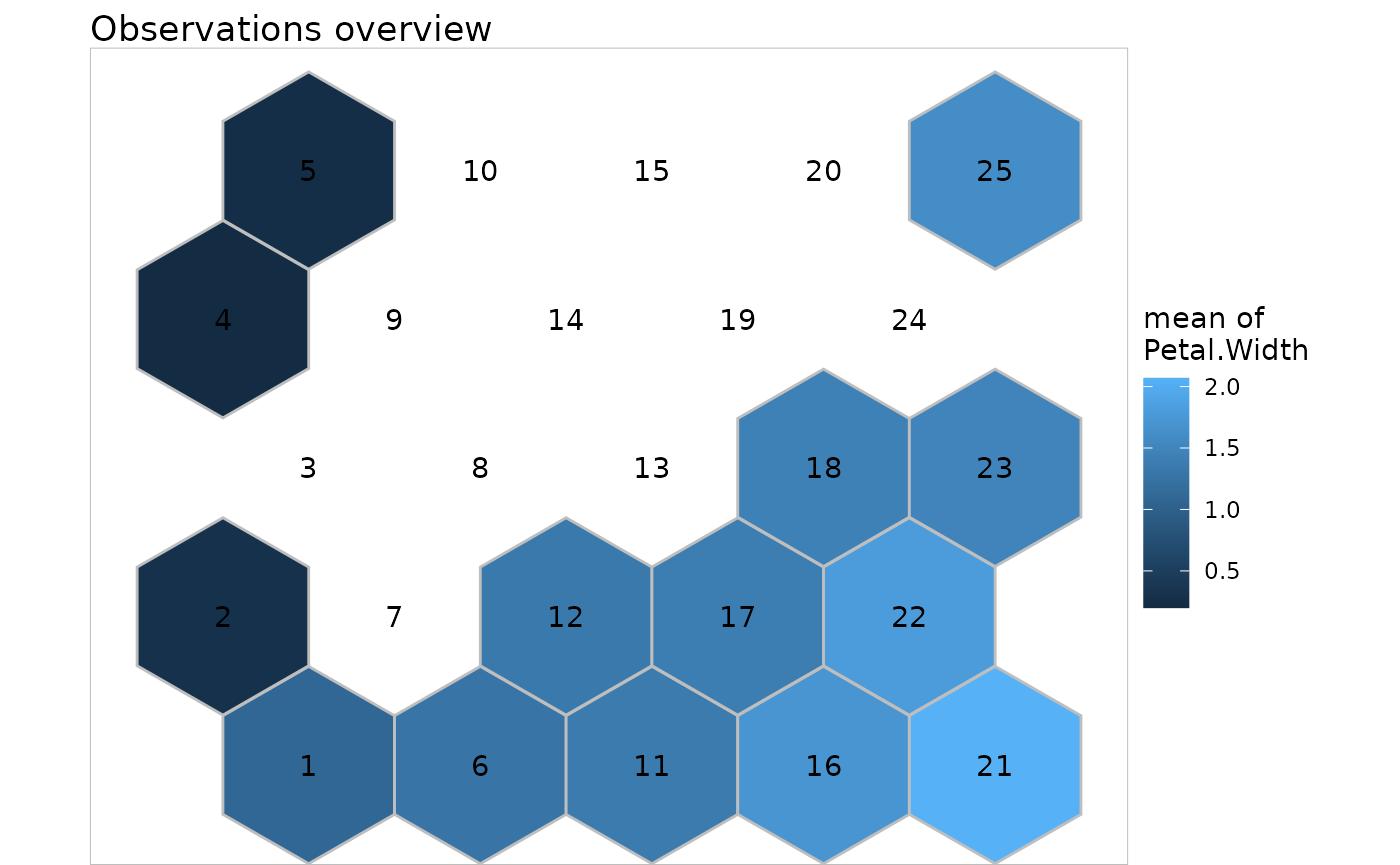
plot(iris.som, what = "prototypes", type = "lines", show.names = TRUE) +
theme(axis.text.x = element_blank())
plot(iris.som, what = "obs", type = "barplot", show.names = TRUE) +
theme(axis.text.x = element_blank())## Warning in min(x): no non-missing arguments to min; returning Inf## Warning in max(x): no non-missing arguments to max; returning -Inf## Warning in min(d[d > tolerance]): no non-missing arguments to min; returning
## Inf## Warning in min(x): no non-missing arguments to min; returning Inf## Warning in max(x): no non-missing arguments to max; returning -Inf## Warning in min(d[d > tolerance]): no non-missing arguments to min; returning
## Inf## Warning in min(x): no non-missing arguments to min; returning Inf## Warning in max(x): no non-missing arguments to max; returning -Inf## Warning in min(d[d > tolerance]): no non-missing arguments to min; returning
## Inf## Warning in min(x): no non-missing arguments to min; returning Inf## Warning in max(x): no non-missing arguments to max; returning -Inf## Warning in min(d[d > tolerance]): no non-missing arguments to min; returning
## Inf## Warning in min(x): no non-missing arguments to min; returning Inf## Warning in max(x): no non-missing arguments to max; returning -Inf## Warning in min(d[d > tolerance]): no non-missing arguments to min; returning
## Inf## Warning in min(x): no non-missing arguments to min; returning Inf## Warning in max(x): no non-missing arguments to max; returning -Inf## Warning in min(d[d > tolerance]): no non-missing arguments to min; returning
## Inf## Warning in min(x): no non-missing arguments to min; returning Inf## Warning in max(x): no non-missing arguments to max; returning -Inf## Warning in min(d[d > tolerance]): no non-missing arguments to min; returning
## Inf## Warning in min(x): no non-missing arguments to min; returning Inf## Warning in max(x): no non-missing arguments to max; returning -Inf## Warning in min(d[d > tolerance]): no non-missing arguments to min; returning
## Inf## Warning in min(x): no non-missing arguments to min; returning Inf## Warning in max(x): no non-missing arguments to max; returning -Inf## Warning in min(d[d > tolerance]): no non-missing arguments to min; returning
## Inf## Warning in min(x): no non-missing arguments to min; returning Inf## Warning in max(x): no non-missing arguments to max; returning -Inf## Warning in min(d[d > tolerance]): no non-missing arguments to min; returning
## Inf## Warning in min(x): no non-missing arguments to min; returning Inf## Warning in max(x): no non-missing arguments to max; returning -Inf## Warning in min(d[d > tolerance]): no non-missing arguments to min; returning
## Inf
Some neurons are empty (no observations affected to them): neurons 3, 7, 8, 9, 10, 13, 14, 15, 19, 20, 24. They are the illustration of a large difference between observations classified in clusters 4-5 with the rest of the observations (to some extend, the same can be said about observations in cluster 25).
Clusters 4-5 are characterized by the following facts (visible on
"color" plots): larger values for Sepal.Width,
smaller values for Petal.Length and
Petal.Width and average values for
Sepal.Length. Similar conclusions are obtained from the
"lines" and "barplot" plots. Please note that,
for these two last plots, it is advised to display the neuron numbers
(option show.names = TRUE) because the hexagonal display is
not properly rendered in them.
More graphics on observations
Individual information on observations in clustered can be obtained with the following plots:
plot(iris.som, what = "obs", type = "boxplot", show.names = TRUE)
plot(iris.som, what = "obs", type = "lines", show.names = TRUE)
plot(iris.som, what = "obs", type = "names", show.names = TRUE)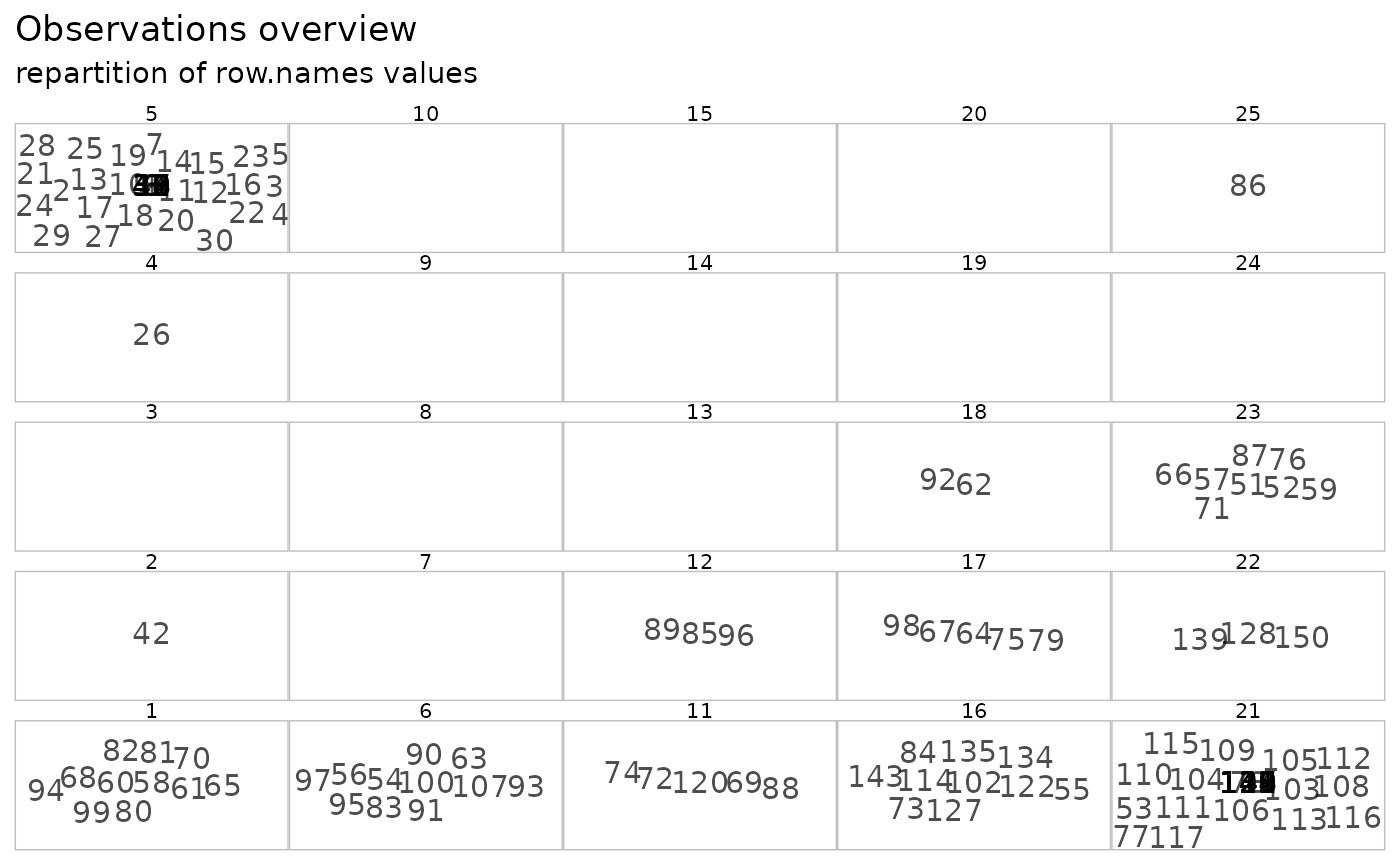
They display either the observation distribution within the cluster
for all the variables in the dataset (for "boxplot" and
"lines") or the names (row numbers by default) of the
observations classified within the cluster.
More graphics on prototypes
Some more graphics handling prototypes have been implemented:
-
"3d"provides the same results as"color"but on a 3 dimensional plot: x is the x dimension of the grid, y is the y dimension of the grid and z is the value of the prototype for the variablevariable(by name or number in the dataset) of the corresponding neuron. For the hexagonal topology, the plot is obtained using a linear interpolation on a regular square grid.
par(mfrow=c(2,2))
plot(iris.som, what = "prototypes", type = "3d", variable = 1)
plot(iris.som, what = "prototypes", type = "3d", variable = 2)
plot(iris.som, what = "prototypes", type = "3d", variable = 3)
plot(iris.som, what = "prototypes", type = "3d", variable = 4)
Also, some graphics are provided to visualize the distance between prototypes on the grid:
plot(iris.som, what = "prototypes", type = "poly.dist", show.names = FALSE)
plot(iris.som, what = "prototypes", type = "umatrix")
plot(iris.som, what = "prototypes", type = "smooth.dist")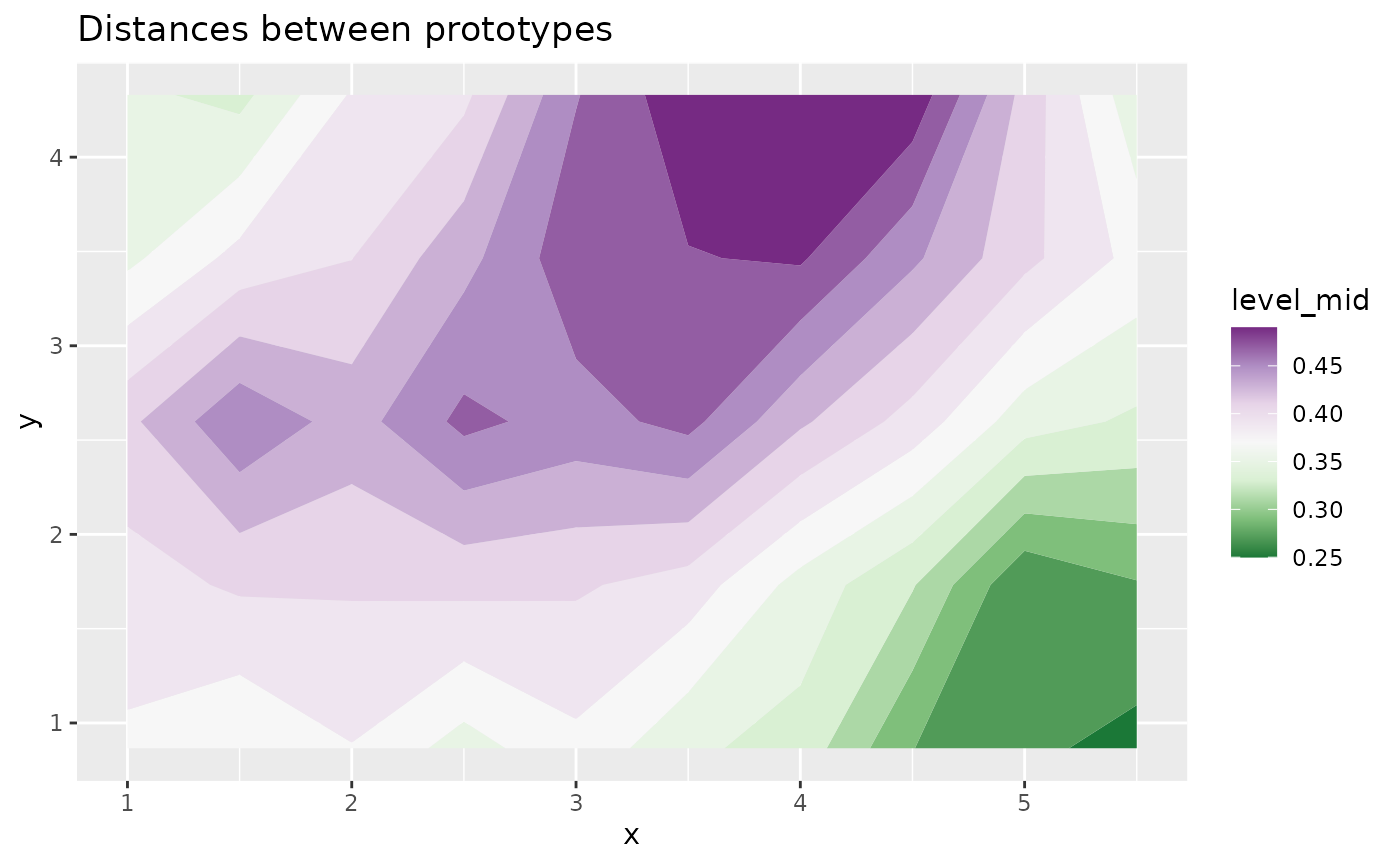
plot(iris.som, what = "prototypes", type = "mds")
plot(iris.som, what = "prototypes", type = "grid.dist")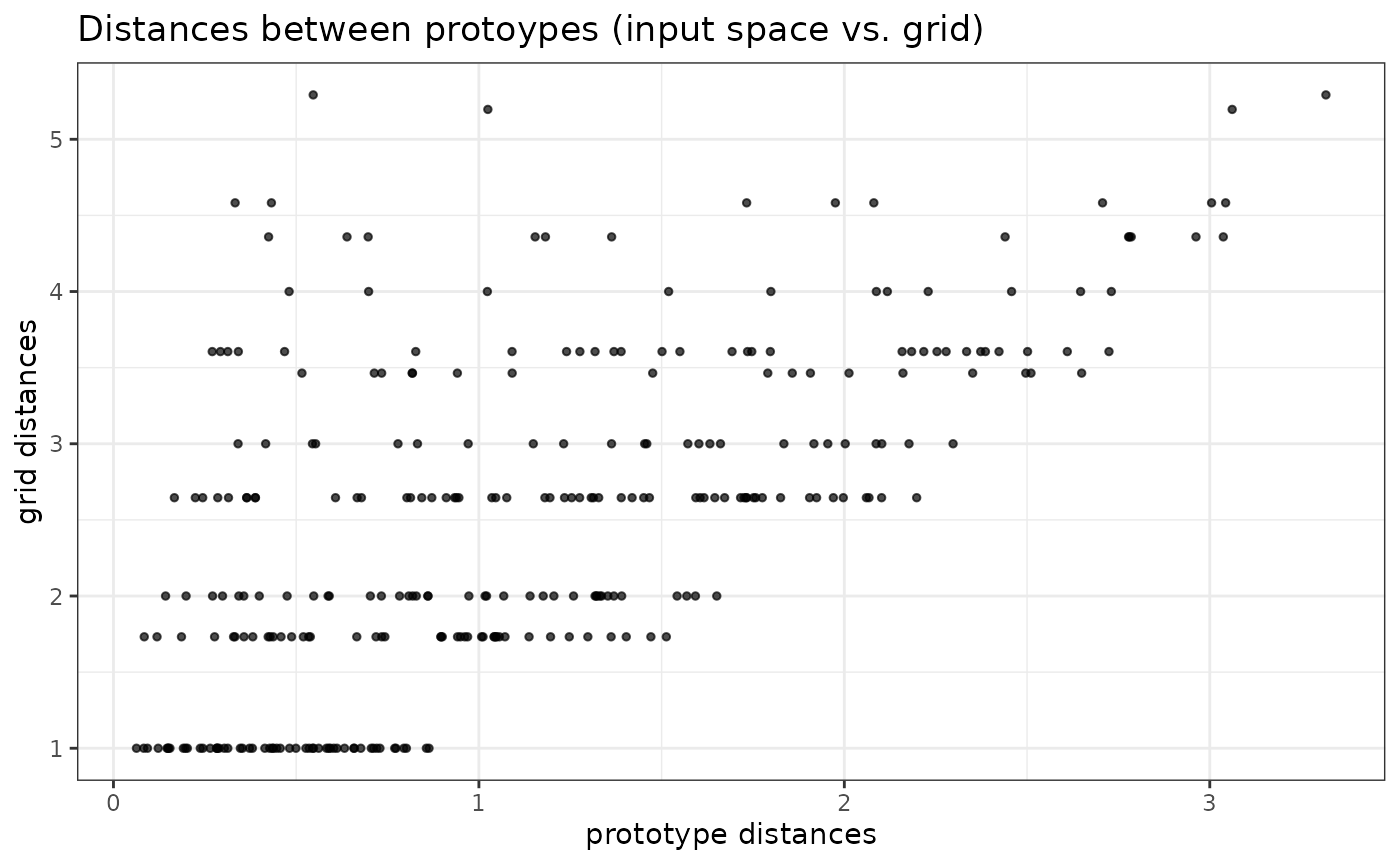
"poly.dist"represents the distances between neighboring prototypes with polygons plotted for each cell of the grid. The smaller the distance between a polygon’s vertex and a cell border, the closer the pair of prototypes. The colors indicates the number of observations in the neuron (white is used for empty neurons);"umatrix"fills the neurons of the grid using colors that represent the average distance between the current prototype and its neighbors;"smooth.dist"plots the mean distance between the current prototype and its neighbors with a color gradation;mdsplots the number of the neuron on a map according to a Multi Dimensional Scaling (MDS) projection;grid.distplots a point for each pair of prototypes, with x coordinates representing the distance between the prototypes in the input space, and y coordinates representing the distance between the corresponding neurons on the grid.
These graphics show that there is a big gap (large distances) between the top left corner and the rest of the map and between the top right corner and the rest of the map (which is consistent with what was already observed in the previous plots). In addition, the bottom right corner of the maps has a few neurons (21, 22, 23) that are very closed to each others.
Graphics showing an additional variable
Additional factor
The clustering can be analyzed together with an additional variable
(here, the flower species) using what = "add":
class(iris$Species)## [1] "factor"
levels(iris$Species)## [1] "setosa" "versicolor" "virginica"
plot(iris.som, what = "add", type = "pie", variable = iris$Species) +
scale_fill_brewer(type = "qual") +
guides(fill = guide_legend(title = "Species"))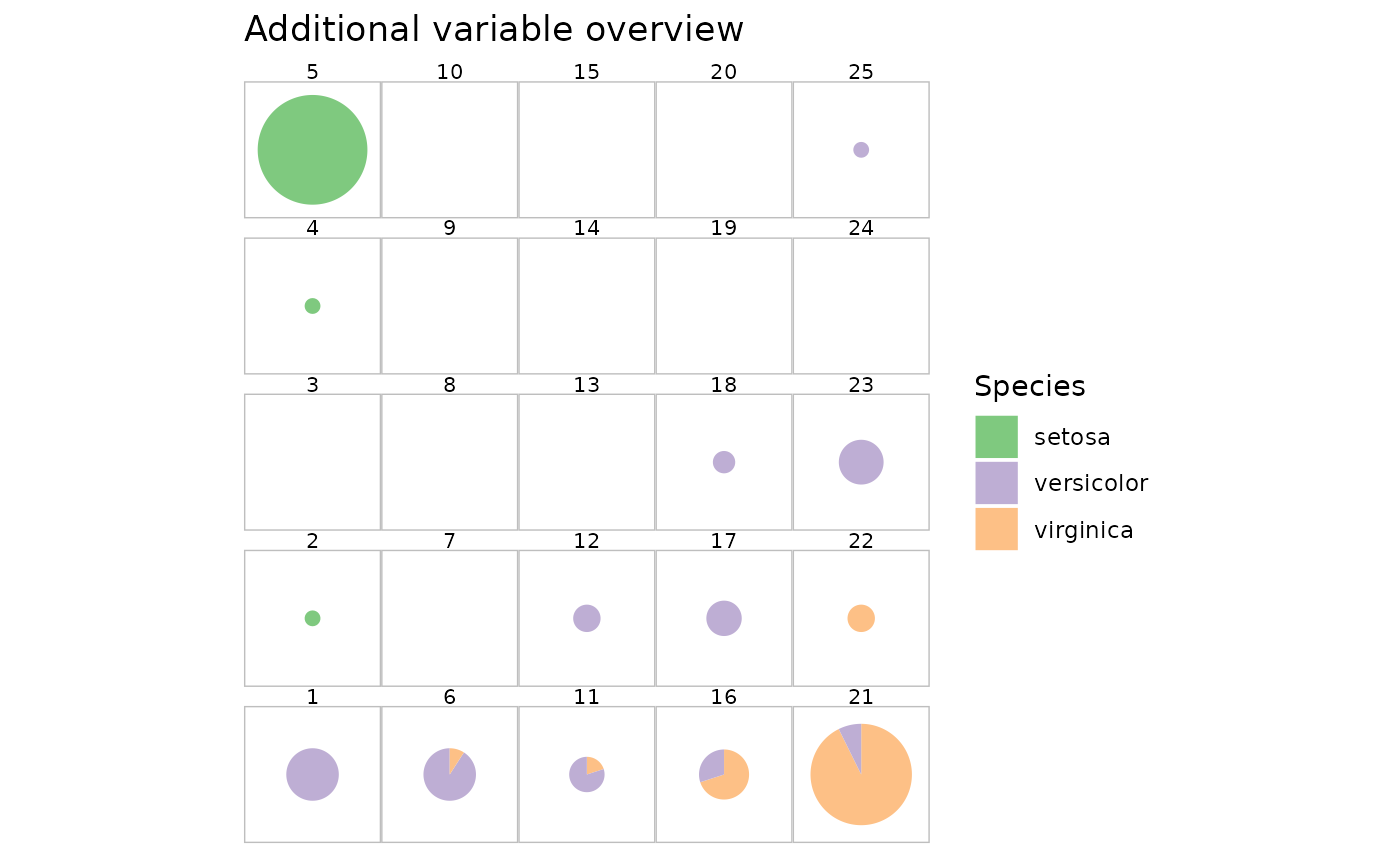
This plot shows that the clustering produced by the SOM is indeed relevant to identify the three different species of iris: they are well separated on the map and almost all clusters only contain one species of iris. The Setosa species is the most distinct from the other two, isolated in the top left corner of the map.
Additional numerical vector
The "color" plot available for "add" is
similar to the "obs" or "prototypes" cases.
Here we choose the first variable of the iris data set as an additional
variable to illustrate its use. We thus obtain the same plot as above
(see section Graphics common to observations and
prototypes).
plot(iris.som, what = "add", type = "color", variable = iris$Sepal.Length,
show.names = FALSE)
Additional numerical matrix or data frame
The "lines", "barplot",
"radar" and "boxplot" plots available for
"add" are similar to the "obs" or
"prototypes" cases.
"words" is only implemented for an additional variable.
In this case, the additional variable must be a contingency matrix: the
words used on the plot are the names of the columns and the presence or
lack of the word is expressed by respectively 1 or 0. The size of the
words on the grid depends on the rate of presence in the observations of
the current neuron. To illustrate its use, we define a contingency table
my.cont.mat that corresponds to the flower Species:
head(my.cont.mat)## setosa versicolor virginica
## [1,] 1 0 0
## [2,] 1 0 0
## [3,] 1 0 0
## [4,] 1 0 0
## [5,] 1 0 0
## [6,] 1 0 0
plot(iris.som, what = "add", type = "words", variable = my.cont.mat,
show.names = FALSE)
Additional non-numerical vector
"names" is similar to the "names" case
implemented for "obs". Here we choose to give the argument
variable the row names of the iris data set: so we obtain
the same plot as above (see More graphics on
observations).

Similarly, this plot can be used with the variable
iris$Species:
plot(iris.som, what = "add", type = "names", variable = iris$Species)
which gives exactly the same plot as before for type
"words" with the contingency matrix corresponding to the
variable iris$Species.
Analyze the projection quality
quality(iris.som)## $topographic
## [1] 0.1466667
##
## $quantization
## [1] 1.22527By default, the quality function calculates both quantization and
topographic errors. It is also possible to specify which one you want
using the argument quality.type.
The topographic error value varies between 0 (good projection quality) and 1 (poor projection quality). Here, the topographic quality of the mapping is equal to 0.15, which means that around 14.7% of the observations have a second best unit in the neighborhood of the best matching unit.
The quantization error is an unbounded positive number. The closer it is to 0, the better the projection quality.
Building super classes from the resulting SOM
In the SOM algorithm, the number of clusters is necessarily close to the number of neurons on the grid (not necessarily equal as some neurons may have no observations assigned to them). This - quite large - number may not suit the original data for a clustering purpose.
A usual way to address clustering with SOM is to perform a
hierarchical clustering on the prototypes. This clustering is directly
available in the package SOMbrero using the function
superClass. To do so, you can first have a quick overview
to decide on the number of super clusters which suits your data.
my.sc <- superClass(iris.som)
plot(my.sc)
## Warning in plot.somSC(my.sc): Impossible to plot the rectangles: no super clusters.By default, the function plots both a dendrogram and the evolution of
the percentage of explained variance. Here, 3 super clusters seem to be
the best choice. The output of superClass is a
somSC class object. Basic methods have been defined for
this class, including a cutree method:
##
## SOM Super Classes
## Initial number of clusters: 25
## Number of super clusters : 3
##
##
## Frequency table
## 1 2 3
## 7 9 9
##
## Clustering
## 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25
## 1 2 2 2 2 1 1 2 2 2 3 1 1 2 2 3 3 3 1 1 3 3 3 3 3
##
##
## ANOVA
##
## Degrees of freedom : 2
##
## F pvalue significativity
## Sepal.Length 178.319 0 ***
## Sepal.Width 60.416 0 ***
## Petal.Length 847.100 0 ***
## Petal.Width 505.974 0 ***
plot(my.sc, plot.var = FALSE)
Like plot.somRes, the function plot.somSC
has an argument type which offers many different plots and
can thus be combined with most of the graphics produced by
plot.somSC:
plot(my.sc, type = "grid")## Warning: Using `size` aesthetic for lines was deprecated in ggplot2 3.4.0.
## ℹ Please use `linewidth` instead.
## ℹ The deprecated feature was likely used in the SOMbrero package.
## Please report the issue at <https://github.com/tuxette/SOMbrero/issues>.
## This warning is displayed once every 8 hours.
## Call `lifecycle::last_lifecycle_warnings()` to see where this warning was
## generated.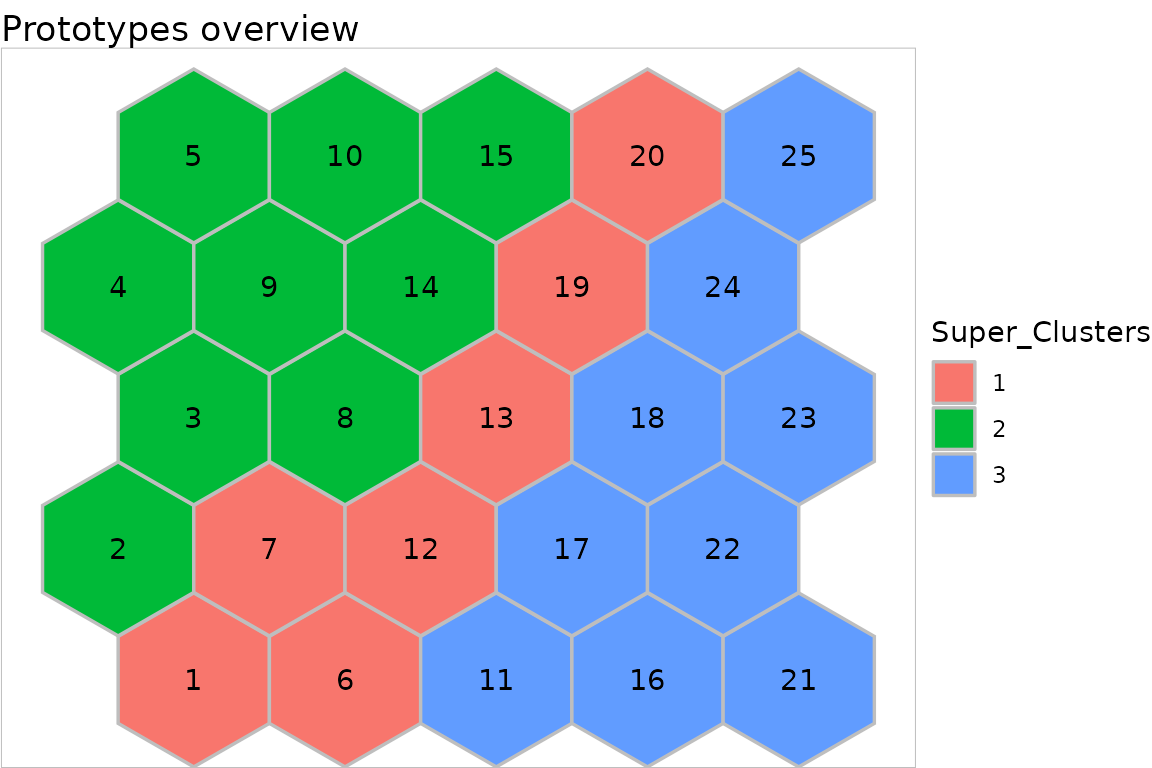
plot(my.sc, type = "dendro3d")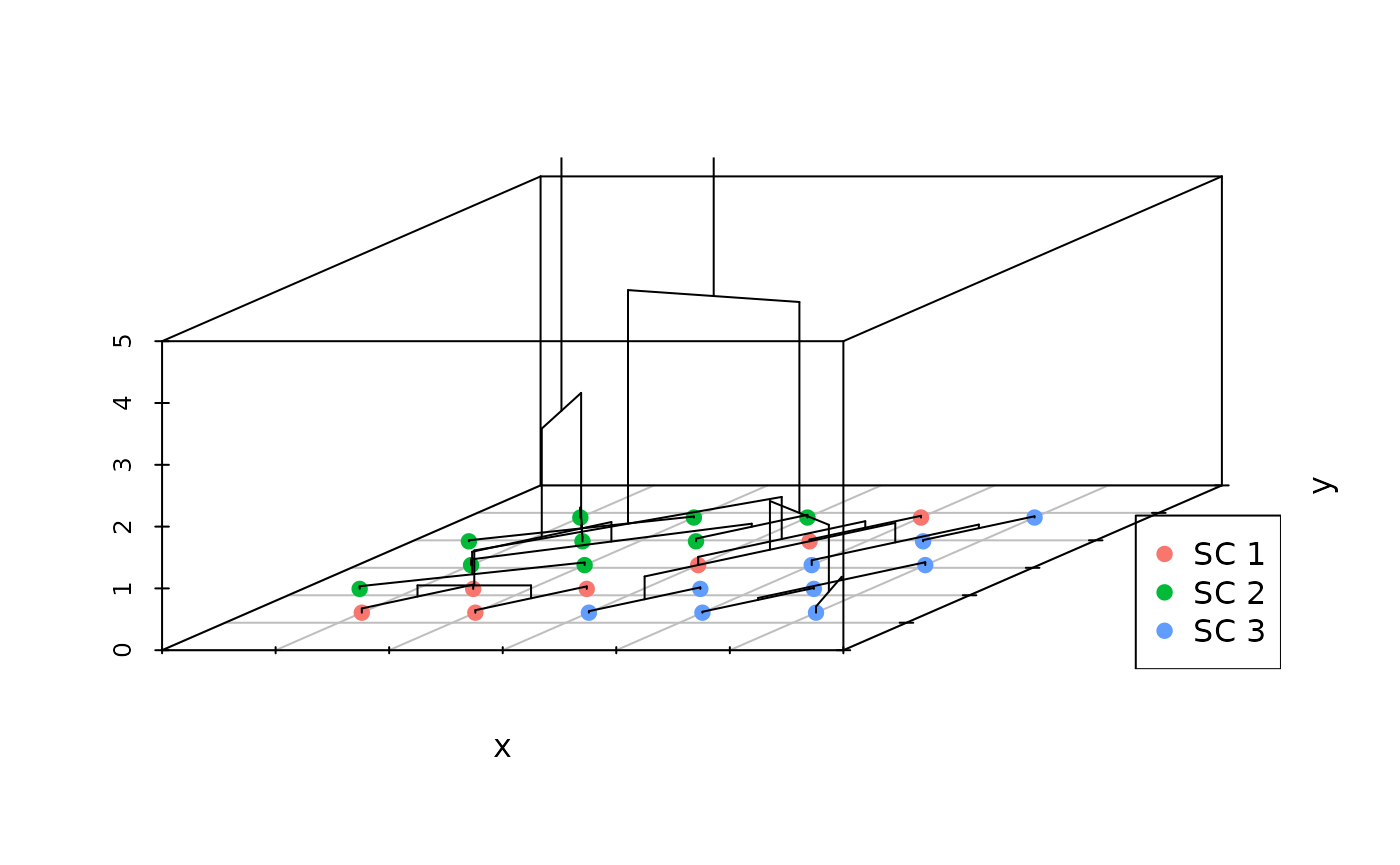
Case "grid" fills the grid with colors according to the
super clustering (and can provide a legend). Case
"dendro3d" plots a 3d dendrogram.
A couple of plots from plot.somRes are also available
for the super clustering. Some identify the super clusters with
colors:
plot(my.sc, what = "obs", type = "hitmap", maxsize = 20)
plot(my.sc, what = "prototypes", type = "lines")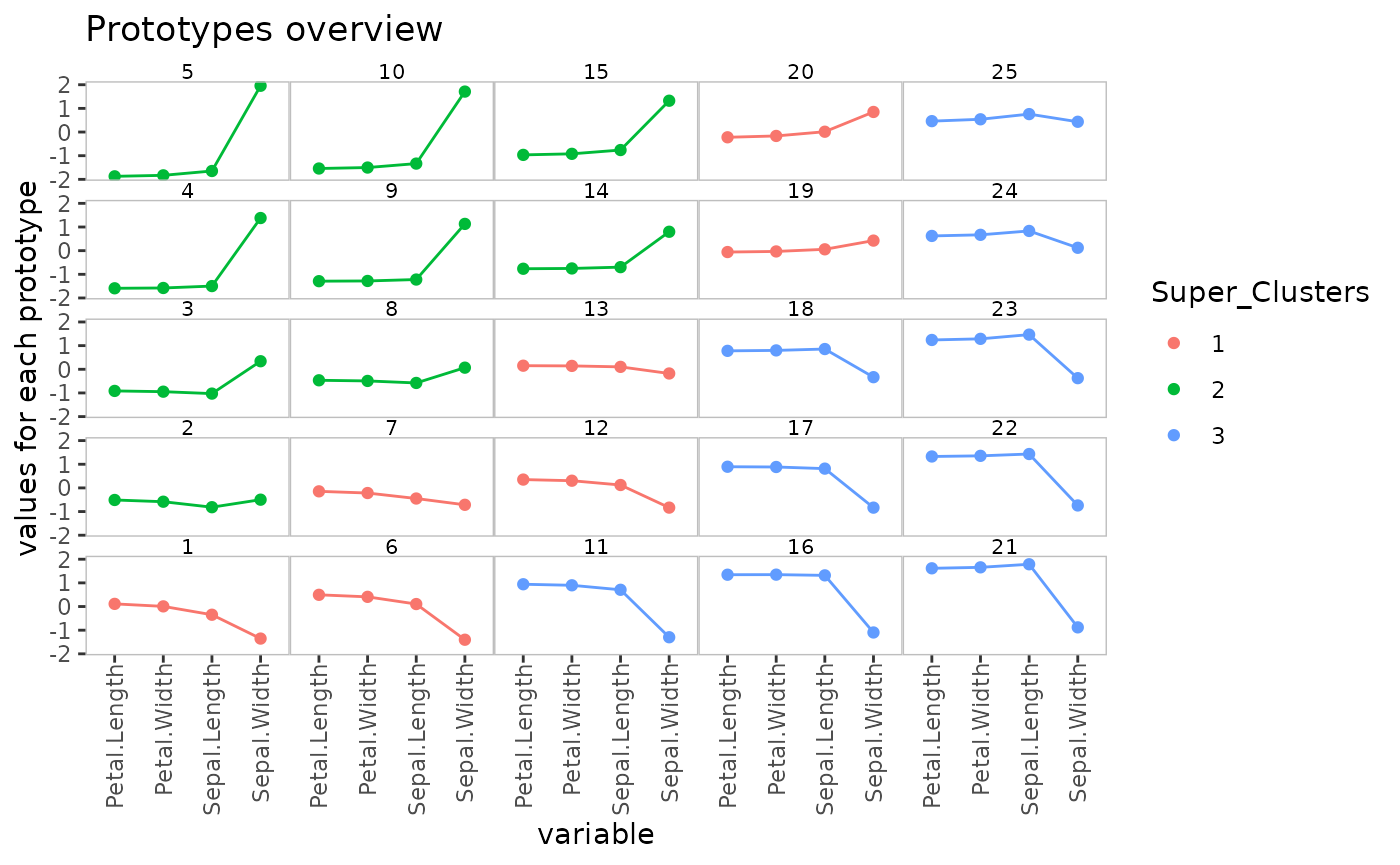
plot(my.sc, what = "prototypes", type = "barplot")
plot(my.sc, what = "prototypes", type = "mds")
And some others identify the super clusters with titles:
plot(my.sc, what = "prototypes", type = "color", variable = "Sepal.Length")
plot(my.sc, what = "prototypes", type = "poly.dist")
It is also possible to consider an additional variable using the
argument what='add':
plot(my.sc, what = "add", type = "pie", variable = iris$Species) +
scale_fill_brewer(type = "qual")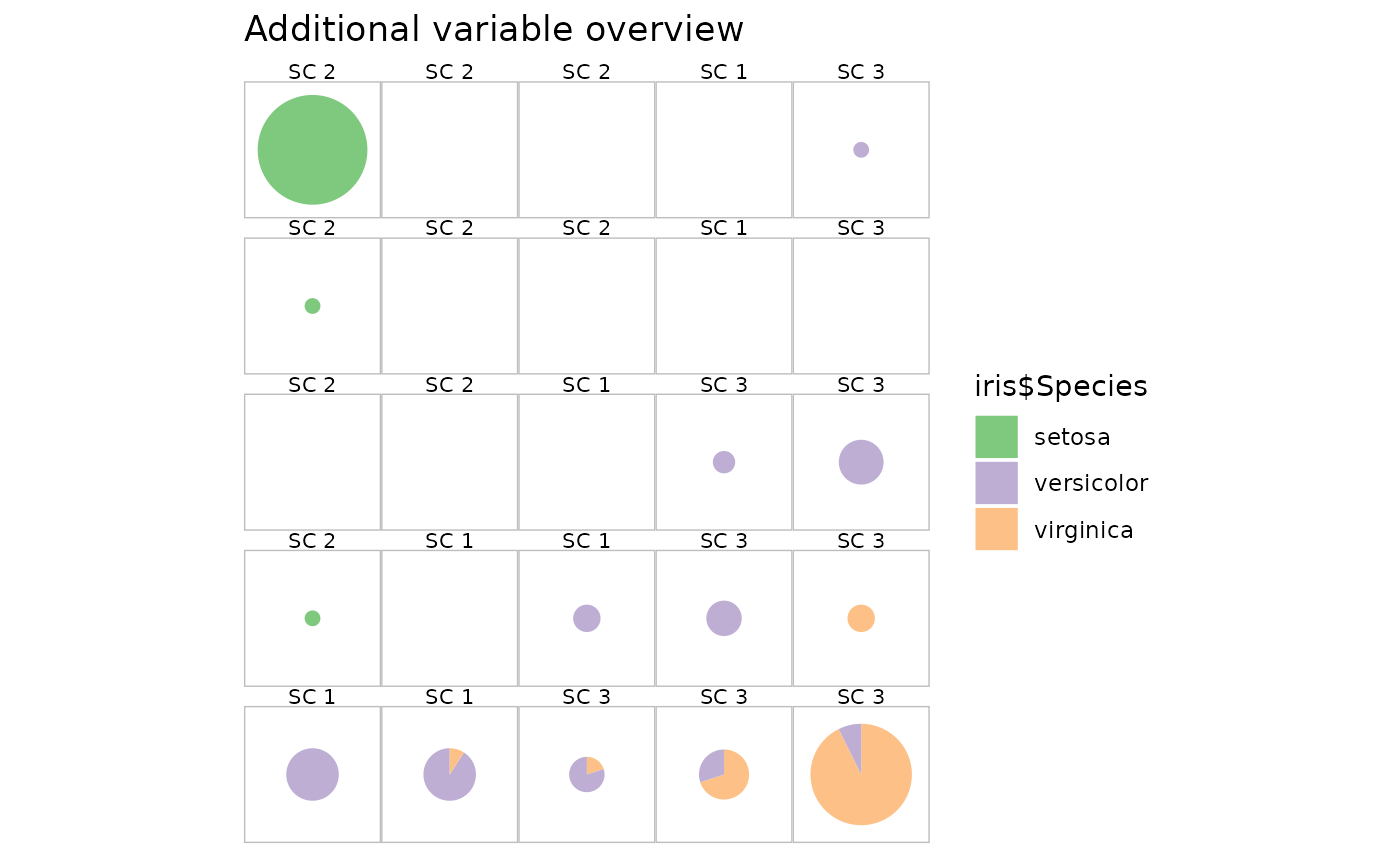
plot(my.sc, what = "add", type = "color", variable = iris$Sepal.Length)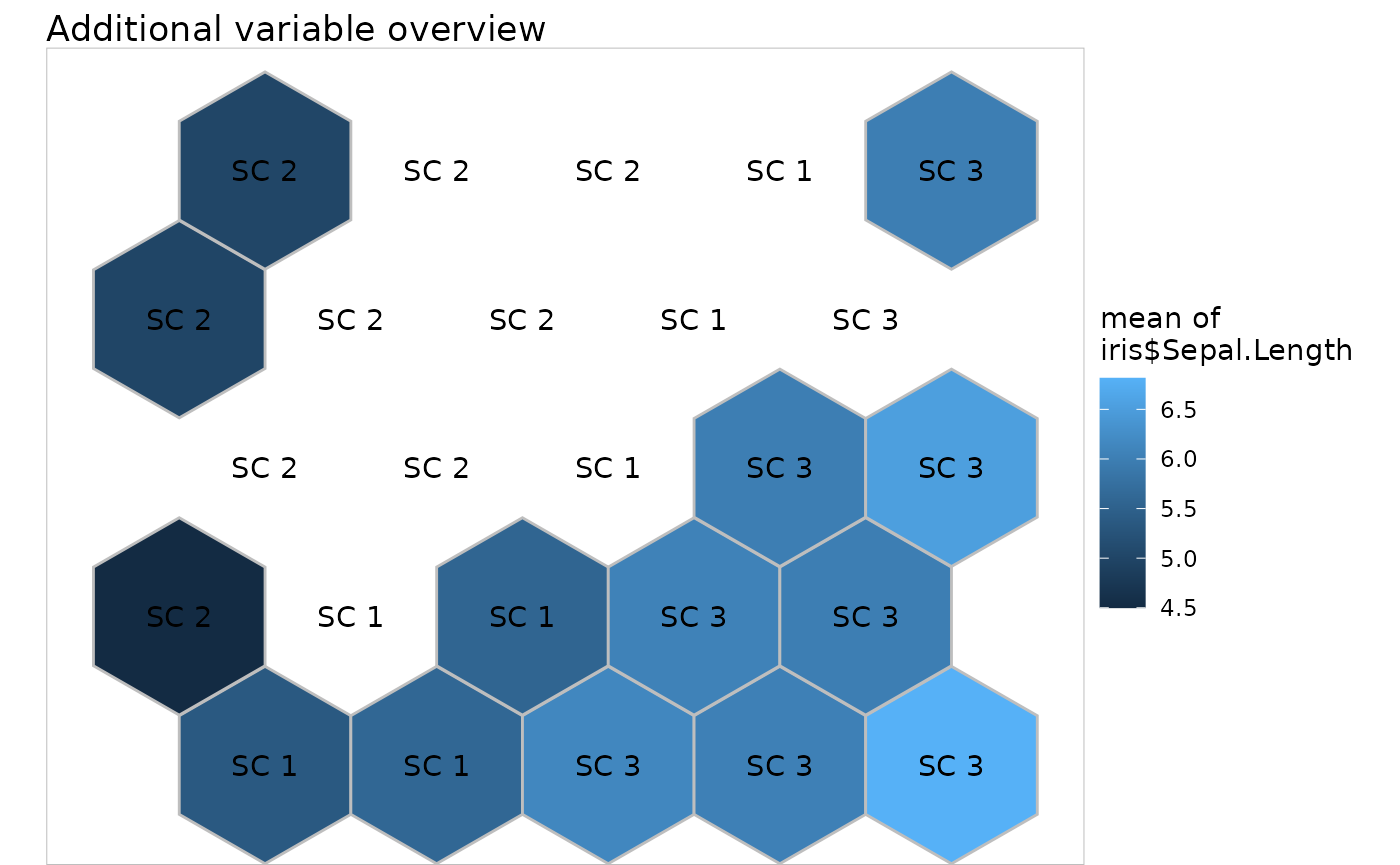
Super cluster number 2 is located at the top left hand corner of the map and associated with the Setosa species. SC 3 is in the opposite corner and associated mainly with Virginica whereas SC 1 is in the diagonal between these two corners and associated with Versicolor.
Session information
This vignette has been compiled with the following environment:
## R version 4.5.1 (2025-06-13)
## Platform: x86_64-pc-linux-gnu
## Running under: Ubuntu 24.04.3 LTS
##
## Matrix products: default
## BLAS: /usr/lib/x86_64-linux-gnu/openblas-pthread/libblas.so.3
## LAPACK: /usr/lib/x86_64-linux-gnu/openblas-pthread/libopenblasp-r0.3.26.so; LAPACK version 3.12.0
##
## locale:
## [1] LC_CTYPE=en_US.UTF-8 LC_NUMERIC=C
## [3] LC_TIME=fr_FR.UTF-8 LC_COLLATE=en_US.UTF-8
## [5] LC_MONETARY=fr_FR.UTF-8 LC_MESSAGES=en_US.UTF-8
## [7] LC_PAPER=fr_FR.UTF-8 LC_NAME=C
## [9] LC_ADDRESS=C LC_TELEPHONE=C
## [11] LC_MEASUREMENT=fr_FR.UTF-8 LC_IDENTIFICATION=C
##
## time zone: Europe/Paris
## tzcode source: system (glibc)
##
## attached base packages:
## [1] stats graphics grDevices utils datasets methods base
##
## other attached packages:
## [1] SOMbrero_1.5.0 markdown_2.0 igraph_2.1.4 ggplot2_4.0.0
##
## loaded via a namespace (and not attached):
## [1] sass_0.4.10 generics_0.1.4 xml2_1.4.0
## [4] stringi_1.8.7 lattice_0.22-7 digest_0.6.37
## [7] magrittr_2.0.4 evaluate_1.0.5 grid_4.5.1
## [10] RColorBrewer_1.1-3 fastmap_1.2.0 plyr_1.8.9
## [13] jsonlite_2.0.0 backports_1.5.0 ggwordcloud_0.6.2
## [16] scales_1.4.0 isoband_0.2.7 textshaping_1.0.3
## [19] jquerylib_0.1.4 cli_3.6.5 crayon_1.5.3
## [22] rlang_1.1.6 scatterplot3d_0.3-44 litedown_0.7
## [25] commonmark_2.0.0 withr_3.0.2 cachem_1.1.0
## [28] yaml_2.3.10 tools_4.5.1 deldir_2.0-4
## [31] memoise_2.0.1 checkmate_2.3.3 dplyr_1.1.4
## [34] colorspace_2.1-2 interp_1.1-6 vctrs_0.6.5
## [37] R6_2.6.1 png_0.1-8 lifecycle_1.0.4
## [40] stringr_1.5.2 fs_1.6.6 htmlwidgets_1.6.4
## [43] ragg_1.5.0 pkgconfig_2.0.3 desc_1.4.3
## [46] hexbin_1.28.5 pkgdown_2.1.3 pillar_1.11.1
## [49] bslib_0.9.0 gtable_0.3.6 glue_1.8.0
## [52] data.table_1.17.8 Rcpp_1.1.0 systemfonts_1.3.1
## [55] xfun_0.53 tibble_3.3.0 tidyselect_1.2.1
## [58] knitr_1.50 farver_2.1.2 htmltools_0.5.8.1
## [61] labeling_0.4.3 rmarkdown_2.30 metR_0.18.2
## [64] compiler_4.5.1 S7_0.2.0 gridtext_0.1.5